
ADVERTORIAL
Eine erfolgreiche, skalierbare Anwendung künstlicher Intelligenz (KI) basiert nicht nur auf der neuesten Forschung zu neuronalen Netzwerken. Ein solides Datenfundament ist vielmehr entscheidend, um nutzbare, robuste und nützliche Applikationen zu entwickeln. Wer dies außer Acht lässt, erstellt tolle Modelle, die sich im Produktivbetrieb nur schwer betreiben lassen. Darum gehört zu einer erfolgreichen und ausgereiften KI-Strategie auch das Thema Datenstrategie mit dem Unterpunkt „Datenprodukte“. In den letzten Jahren hieß es bei KI-Modellen oft: tiefer, größer, breiter. Google veröffentlichte zuletzt „Switch Transformer“ – das bisher größte KI-Modell mit 1.600 Milliarden Parametern. Insbesondere Sprachmodelle wurden zuletzt vor allem durch größere Massen an Daten verbessert und nicht durch raffiniertere Methoden. Letztlich wirken größere Modelle natürlich auch beeindruckender als der immerwährende – aber tatsächlich lohnende – Kampf um Datenqualität und besseres Datenmanagement.
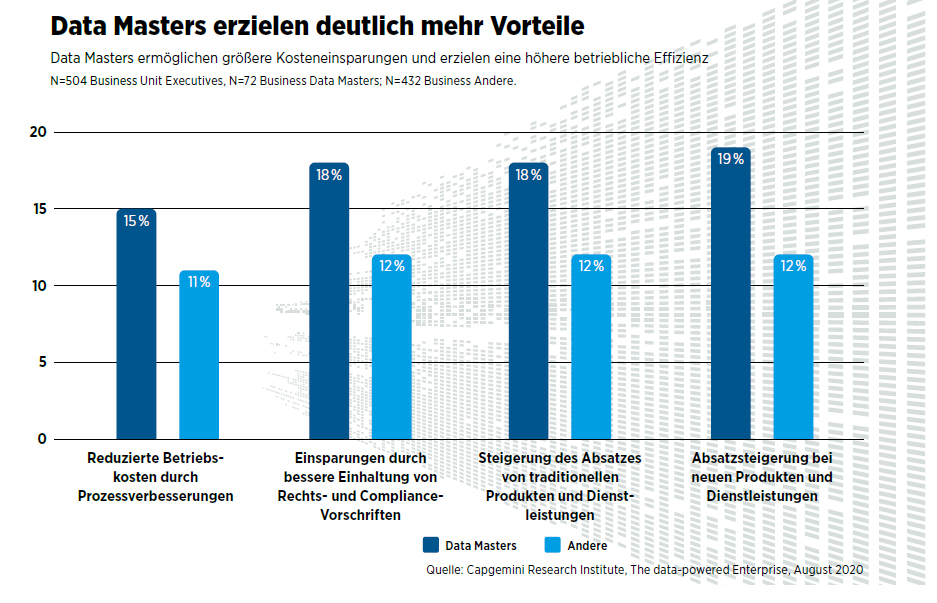
Mit der Kampagne „From Model-centric to Data-centric AI” startete KI-Guru Andrew Ng vor Kurzem eine Initiative, um Daten zurück in den Fokus zu rücken. Und viele Architekturdiskussionen sind mittlerweile vom Begriff des „Data Mesh“ durchzogen – eine Strategie, die Daten als „Bürger erster Klasse“ behandelt und nicht als Nebenprodukt eines Geschäftsprozesses. Auch die Marktforschung des Capgemini Research Institute ist zu dem Schluss gekommen, dass Firmen, die Daten meistern und gekonnt teilen, Wettbewerbsvorteile realisieren.
Nur FAIRe Daten sind gute Daten
Das bedeuten diese Entwicklungen nun für Sie als deutsches Unternehmen? Es lohnt sich für Sie, wenn Sie damit beginnen, auch Daten als „Produkt“ zu behandeln und einen Product Owner definieren – am besten von der Fachseite und nicht aus der IT. Sorgen Sie gemeinsam dafür, dass Ihre Daten FAIR werden:
- Findable (auffindbar von Menschen und Maschinen)
- Accessible (zugänglich über klare Autorisierungsprozesse und technische Protokolle)
- Interoperable (gut verknüpfbar mit anderen Datenquellen)
- Reusable (wiederverwendbar, um nicht wieder bei „Null“ beginnen zu müssen)
Machen Sie sich mit dem Konzept des „Data Mesh“ vertraut und realisieren Sie Ihre Chancen durchs Teilen von Daten in Ihrer Lieferkette oder auch mit anderen Marktteilnehmern. Mit diesen Schritten entlasten Sie Ihre Data Science Organisation und setzen deren Kräfte für neue, kreative KI-Modelle und Business-Entscheidungen frei.
Wie Sie dabei vorgehen, was es zu vermeiden gilt, und wie Sie Daten und Modelle beherrschen können, erfahren Sie u. a. in unseren Studien
![]()
Das vollständige Journal können Sie sich hier kostenlos herunterladen: