Ein prominentes Beispiel sind (global) integrierte Lieferketten, die seit Jahren unter hohem Druck stehen. Die Resilienz dieser Lieferketten ist eine der aktuellen Kernherausforderungen vieler Unternehmen. Im Gegensatz zu Textdaten, die in vielfältiger Form im Internet verfügbar sind, sind Lieferkettendaten spezieller und oft gut geschützt.
Daten sind nicht das grundsätzliche Hindernis für KI-Methoden in Lieferketten
Es ist ein weit verbreiteter Gedanke, dass Unternehmen riesige Menge verwertbarer Daten benötigen, damit KI Mehrwert schaffen kann. Bezogen auf die Datenmenge, die benötigt wird, um riesige neuronale Netze zu trainieren, wie sie hinter großen Sprachmodellen stehen, ist diese Vorstellung richtig. Glücklicherweise müssen nicht alle Probleme mit neuronalen Netzen mit Milliarden von Parametern gelöst werden, und nicht alle Probleme erfordern so mächtige Algorithmen wie ChatGPT. Außerdem gibt es verschiedene Möglichkeiten, einen Algorithmus zu trainieren. Große Sprachmodelle werden (meistens) mittels überwachten Lernens trainiert, was große Mengen an beschrifteten Daten erfordert. Dabei handelt es sich um Daten, die manuell beschriftet werden müssen, wie z.B. Bilder, bei denen ein Experte einen Versicherungsbetrug bestätigt oder nicht. Andere KI-Techniken kommen dagegen mit deutlich weniger Daten aus, wenn im Vorfeld mehr Informationen über das Problem bekannt sind.
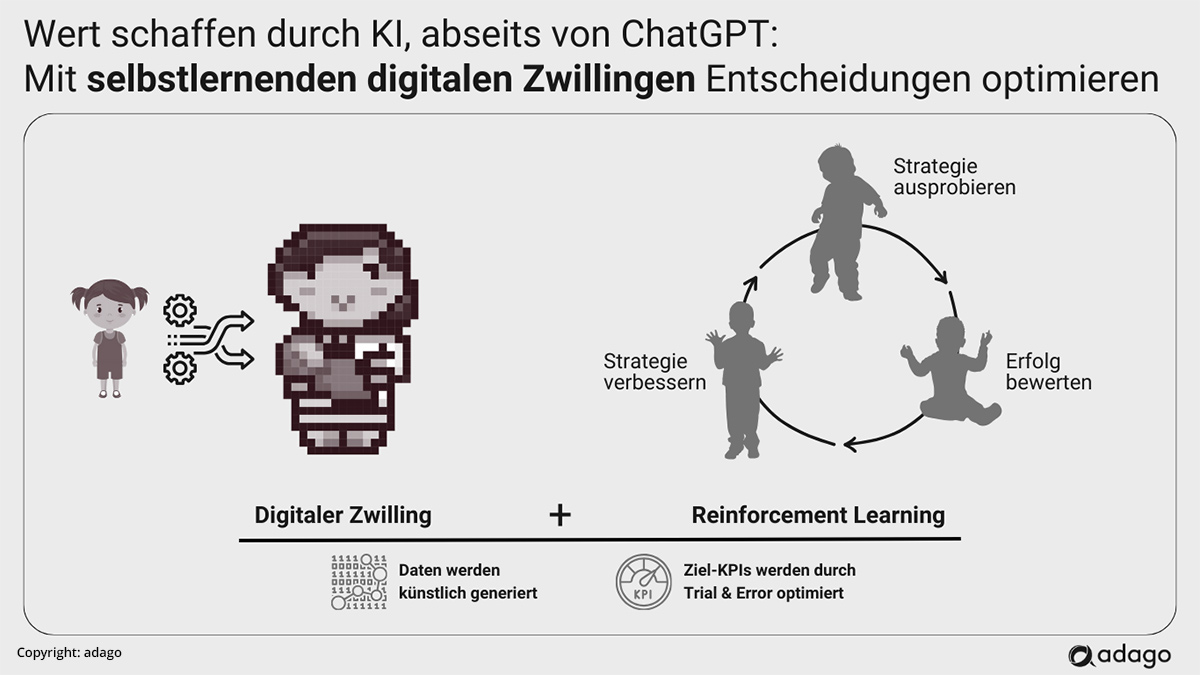
Eine dieser Techniken ist das sogenannte Reinforcement Learning (RL). RL ist ein Verfahren zum Erlernen optimaler Entscheidungen bei einem Problem, das Handlungen erfordert. Gängige Beispiele aus der Wirtschaft sind Roboter, die darauf trainiert werden, eine bestimmte Aufgabe auszuführen. Oder eine Lieferkette, in der Disponenten Artikel versenden und nachbestellen. Im Gegensatz zum überwachten Lernen erzeugen die klassischen Algorithmen des RL eigene Daten, wenn die Grundprinzipien bekannt sind. Reinforcement Learning ist nichts anderes als ein cleverer Weg, durch wiederholtes Spielen die besten Spielzüge mittels Trial-and-Error zu erlernen. Dazu muss festgelegt werden, was ein gutes Ergebnis bedeutet. In der Informatik bezeichnet man dieses Ergebnis als Belohnung, in der Geschäftswelt ist das ein KPI (oder mehrere KPIs). Bei Lieferketten könnte es sich etwa um Bestände oder Servicelevel handeln, die besonders niedrig oder hoch sein sollen. Im Idealfall spielt man das Spiel dann in einem digitalen Zwilling, also in einer vollständig virtuellen Umgebung. Nicht einmal oder zwei Mal, sondern hunderte Millionen Mal. In jeder Runde wird eine bestimmte Strategie verfolgt, um Entscheidungen zu treffen. Je nachdem, welche Belohnung es in einer Runde gibt, wird die Strategie verbessert. Es ist ein bisschen so, wie wenn ein kleines Kind laufen lernt: Eine Bewegung ausprobieren, sehen, ob sie funktioniert hat, sie verbessern, es noch einmal versuchen. Ganz einfach. Abgesehen von der für einen Computer sehr anspruchsvollen Aufgabe, eine Strategie zu verbessern.
Daten nutzen, um ein Problem zu beschreiben, nicht, um es direkt zu lösen
Was hat das nun mit Daten zu tun? Wenn ein Spiel auf einem Computer gespielt werden kann, dann werden dabei künstlich Daten erzeugt – auf externe Daten kann man also verzichten. Vorausgesetzt, das Spiel ist bekannt. Wenn Sie Ihre Lieferkette mithilfe von RL optimieren wollen, müssen Sie sämtliche Regeln für diese Lieferkette kennen. Was soll verschickt werden, wie lange dauert es von Lager A nach Lager B zu verschicken und so weiter. Diese Regeln können aus historischen Daten extrahiert und in einen digitalen Zwilling der Lieferkette übersetzt werden. Wird dies so gemacht, dass RL-Algorithmen angewendet werden können, um das „Lieferkettenspiel“ für eine bestimmte Anzahl KPIs zu optimieren, spricht man von einem selbstlernenden digitalen Zwilling. Die gute Nachricht ist: Dieser Ansatz zur Optimierung der Lieferkette ist dank der hohen verfügbaren Rechenkapazitäten und der gesammelten historischen Daten jetzt auch für komplexe Systeme in greifbare Nähe gerückt.
Autor:

Als Experte für die mathematische Modellierung stochastischer Prozesse ist Leif Döring Co-Founder und Chief Scientist von adago und unterstützt Unternehmen bei datengetriebenen Fragestellungen. Er studierte Mathematik und Informatik in Konstanz und Yale. Nach der Promotion an der TU Berlin und Forschungsaufenthalten in Oxford, Paris und Zürich wurde er 2015 an die Universität Mannheim berufen, wo er heute den Lehrstuhl für Wahrscheinlichkeitstheorie innehat.